
EMPIRE XPU is a 3D EM modeling tool based on finite difference time domain (FDTD) for antennas, microwave circuits, EM chip design and more. Due to increasing complexity, higher package density and the need to take environmental considerations into account the simulation effort is steadily rising. Therefore, simulation acceleration techniques are becoming increasingly important.
Solutions based on graphic cards (GPU) are expensive and limited in usable memory because only the on-board memory of the GPU may be used. With its new release the 3D EM solver EMPIRE XPU 7.1 has been further optimized for new CPU architectures to increase the simulation performance to approximately 8 GCells/s. The XPU technology is a smart implementation of the FDTD algorithm on modern CPU architectures. It can drastically reduce simulation times while maintaining full access to the available RAM.
XPU Acceleration Method
The well known FDTD method keeps samples of three electric fields and three magnetic field components per unit cell in the computer memory. The fields are calculated independently of time, overwriting the complete E-field and H-field with new samples in one step. A conventional code implementation requires reading and writing the complete E-field and H-field to the RAM each time step. On a state-of-the-art PC (Intel Core i7, 8 cores, 3 GHz clock speed and DDR4 RAM) the memory bandwidth is 68 GByte/s which yields a maximum FDTD performance of about 900 million cells per second (MCells/s).
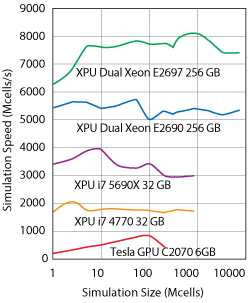
Figure 1 Performance vs. simulation size on different processors.
The performance on the CPU itself is about 8 times higher, indicating that the memory access time is the bottleneck. Conversely, the memory bandwidth of the last level caches is 768 GB/s which is much higher than the RAM access time. EMPIRE features a smart algorithm which can exploit the high computation speed of the CPU by executing multiple time steps in a certain number of planes within the L3 cache before exchanging the data with the RAM. The optimum number of planes and strategy is determined, during the initial simulation phase in EMPIRE.
On multi-CPU machines special care has to be taken if data has to be written into memory modules which are associated to other CPUs. By enabling the Non-Uniform Memory Architecture (NUMA) and code optimization the simulation performance is further increased by EMPIRE XPU 7.1.
Figure 1 shows the simulation speed versus simulation size on different processors. As a reference, the red line shows the performance of a Tesla GPU card. Here the performance varies with simulation size and the simulation size is limited due to available memory. Other curves show the EMPIRE performance on consumer PCs (Intel core i7) and workstations (e.g., Intel dual Xeon, E5-2697 V3). A high performance is obtained for all simulation sizes and larger simulation problems can be solved due to access to the complete RAM (approximately 6 billion cells compared to 200 million cells on GPU).
Benchmark: Antennas with Radomes
In order to obtain an accurate prediction of antenna characteristics, the antenna environment has to be included in state-of-the-art EM simulations. The presence of a radome can change the antenna gain and beamwidth as well as increase sidelobes. For example, in Figure 2 a parabolic reflector is fed by a waveguide horn and enclosed by a radome (permittivity = 5, thickness = 7 mm). The operating frequency is 15 to 25 GHz and the simulation area is about 75 x 75 x 40 cm. Using a maximum resolution of 15 cells per minimum wavelength yields a mesh with 5 billion cells. EMPIRE XPU 7.1 uses smart caching of simulation coefficients to minimize the memory effort. The required memory exceeds 114 GByte which would not be possible using GPU cards.
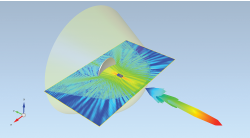
Figure 2 Near and far fields of a reflector antenna with radome at 25 GHz.
In this example, the simulation performance of 3.6 GCells/s is obtained on a Dual Xeon E5-2690 workstation and the 30 dB energy decay limit is obtained after 11,000 time steps in 4 hours 20 minutes. Near and far fields at 25 GHz in Figure 2 show that the radome has substantial influence on both near field and far field patterns and must be taken into account for proper EM design.
Car-to-Car communication
The car-to-car (C2C) communication project is a European initiative for the development of data exchange between vehicles with the aim to increase safety or to optimize the traffic flow. The operating frequency chosen is 5.6 GHz. With EMPIRE XPU 7.1 simulations an accurate prediction of the propagation channel is possible. InFigure 3 a scenario is depicted where two cars are transmitting while others are receiving the signals.
All details relating to the car such as the body, screen, interior or wheels were taken into account. This simulation requires about 4 billion cells and a memory usage of 96 GB RAM, including near and far field recordings. The simulation is carried out in about 5 hours on an Intel dual Xeon workstation E5-2697 V3 with a performance of 5 GCells/s, calculating 25,000 time steps to reach 30 dB energy decay.
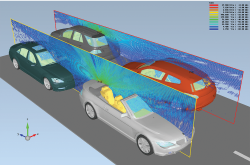
Figure 3 Electric field of a car-to-car communication link at 5.6 GHz.
The acceleration technique utilized by EMPIRE XPU 7.1 enables fast and efficient FDTD simulations on modern CPUs. A smart time stepping algorithm facilitates the calculation of multiple FDTD time steps in the cache memory of the CPU. This increases the simulation speed drastically as the simulation speed is no longer limited by the main memory interface. The whole RAM memory of the PC is quickly accessible for the EM simulation.
The examples given above illustrate when EMPIRE XPU 7.1 is applied to simulations of a 25 GHz reflector antenna with radome and a car-to-car communication link. Such applications requiring a large amount of RAM memory can be easily simulated with the XPU technique on conventional workstations, while a calculation on a GPU card would fail due to limited available memory.
IMST GmbH
Kamp-Lintfort, Germany
www.empire.de
See IMST at IMS Booth 2522